
一、前言
大数据、人工智能机器学习实战性归纳总结,实例可以直接运行。如果您读后感觉总结的有收获请关注我,支持我进一步为大家做贡献,支持我就是支持科技的发展谢谢。
大家在学习机器学习的时候大多数都是以一元线性回归入门,使用的是Python工具,由于机器学习入门比较难,很多人一开始弄不清楚头绪,其实一元线性回归在拟合曲线计算回归系数的时候还是有一些步骤的,比如最小二乘法,求残差,通过求导求极值。为了是大家能够快速看见结果,然后再慢慢的研习里面的原理,特给大家总结此文章,目的为:
1、了解一元线性回归的拟合过程
2、能够使用Python实现一元线性回归的拟合过程
3、了解一元线性模型拟合优度的测量评价
本案例的实验环境为:
1、Python3.6以上版本
2、Python的基本数学库numpy、pandans、matplotlib、sklearn
3、Python的PyCharm开发环境
二、案例描述
一般来说房屋的售价和面积有很大的关系,也就是说面积是房屋的售价很大的一个权重,下面是一个房屋销售的数据如下:

在2000年以前某地区正常来说房屋售价为2000元/平方米,在以后的时间里有可能每个月房价稍稍有点浮动,但是浮动不大,整体还是近似的处于线性状态,请根据以上数据建立线性回归方程,并预测8平方米的售价。
三、一元线性回归的一个简单实现
1、概述
一元线性回归分析预测法,是根据自变量x和因变量Y的相关关系,建立x与Y的线性回归方程进行预测的方法。
两变量之间的关系
(1)函数关系:当自变量取值一定时,因变量取值由它唯一确定,这是确定关系。
(2)相关关系:当自变量取值一定时,因变量的取值带有一定的随机性,(例子:一块农田的水稻产量与施肥量之间的关系)这是不确定关系。
我们主要研究不确定型的函数关系,如收入与受教育程度之间的关系,等等问题。 但它们之间存在明显的相互关系(称为相关关系),又是不确定的。
使用最小二乘法求解回归系数:
最小二乘法公式是一个数学的公式,在数学上称为曲线拟合,此处所讲最小二乘法,专指线性回归方程!最小二乘法公式为b=y(平均)-a*x(平均)。
2、一元线性回归检验指标:拟合优度
拟合优度就是相关系数的平方R^2,R^2最大值为1。R^2的值越接近1,说明回归直线对观测值的拟合程度越好;反之,R^2的值越小,说明回归直线对观测值的拟合程度越差。r2_score函数是计算 R^{2}

3、一元线性回归模型拟合效果的判别:均方误差MSE
均方误差MSE用来检测预测值和真实值之间的偏差,

先给出已经调试通过的源代码:
import numpy as np
from matplotlib import pyplot as plt
from sklearn.linear_model import LinearRegression
# x轴数据
x_data = np.arange(7)
# y轴数据
y_data = np.array([2,4,6.09,8,10.1,12.1,14.06])
print(x_data)
print(y_data)
# 转换成sklearn框架能够识别的维度
x_data = x_data[:, np.newaxis]
y_data = y_data[:, np.newaxis]
# 建立模型
model = LinearRegression()
# 开始训练
model.fit(x_data, y_data)
# 斜率 print("coefficients: ", model.coef_)
w = model.coef_[0]
# 截距
print("intercept: ", model.intercept_)
b = model.intercept_
# 测试
x_test = np.array([[7]])
predict = model.predict(x_test)
print("predict: ", predict)
plt.plot(x_data, y_data, "b.")
plt.plot(x_data, model.predict(x_data), "r")
#plt.plot(x_data, b + w * x_data, "r")
plt.show()
下面详细说下实现步骤,根据步骤和数据大家对照自己的教材逐步体会原理,消化最小二乘法等推导步骤:
组织数据
步骤1:组织训练数据
x_data = np.arange(7)
上述数据代表1平方米、2平方米...7平方米
y_data = np.array([2,4,6.09,8,10.1,12.1,14.06])
步骤2 :组织测试数据
上述数据代表1平方米售价2000元、2平方米售价4千元、3平方米售价6.09元...
为了简单起见,在拟合完毕直线后给出测试数据是1平方米、2平方米...7平方米,8平方米,即:
x_test = np.array([[7]])
就是预测房价8平方米的价格是多少
建立回归方程
通过Python提供的一元线性回归方法将训练集x_data、y_data来训练模型,如下所示:
model = LinearRegression()
# 开始训练
model.fit(x_data, y_data)预测房价
将测试数据x_data = np.arange(7)输入:
predict = model.predict(x_test)
print("predict: ", predict)
可以得到房价8平米的预测值为:predict: [[16.10571429]]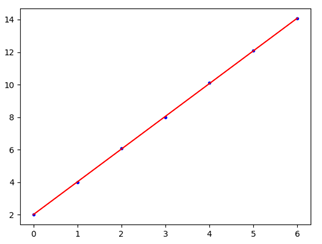
拟合优度分析
Python提供的相应的函数为:
sklearn.metrics.r2_score(y_true, y_pred, sample_weight=None, multioutput=’uniform_average’)
计算我们的拟合优度:
from sklearn.metrics import r2_score
y_true = [2, 4, 6, 8,10,12,14]
y_pred = [2,4,6.09,8,10.1,12.1,14.06]
print(r2_score(y_true, y_pred))输出结果为:0.9997169642857143
说明我们的线性拟合度还是十分不错的。
均方误差MSE检验
Python为我们提供了均方误差MSE检验的方法mean_squared_error(),实现如下:
#真实值
y_true = [2, 4, 6, 8,10,12,14]
#预测值
y_pred = [2,4,6.09,8,10.1,12.1,14.06]
from sklearn.metrics import mean_squared_error
print(mean_squared_error(y_true,y_pred))
结果为:0.004528571428571414
从结果来看,均方误差非常小,看来拟合的效果还是很理想的。
相关文章
【远古沉默】装备系统深度攻略——从断臂到神装,进阶必读

丝路传说手游:宠物玩法详细讲解

《修仙家族模拟器2》罪恶值:红名危机与解决之道

卷死重坦的火力!顶级重炮“菲利斯”强势出击

新一代中坦“卷王”就是它?不带垂稳都可以体验百步穿杨!

三国杀:高价低配排行榜,花了100宝珠还要强度,好事都想要?
